Design Pattern
AI UI Patterns
Building AI-powered interfaces – from chatbots to intelligent assistants – requires careful integration of backend AI services with reactive UI components. In this chapter, we explore design patterns in React for such interfaces, focusing on two implementations: a plain React app (using Vite) and a Next.js app. We’ll use OpenAI’s API (via the Vercel AI SDK) as our AI engine, and TailwindCSS for styling. Key topics include prompt management, streaming responses, input debouncing, error handling, and how these patterns differ between Vite and Next.js. We also highlight reusable component patterns and Vercel’s AI UI components (AI Elements) for building polished chat UIs.
Note: While this article uses OpenAI as an example, the Vercel AI SDK supports multiple model providers including Gemini, OpenAI, and Anthropic. You can easily swap between providers through the SDK’s unified interface – we’re just choosing one option for demonstration purposes.
Introduction: AI Interfaces in React
AI-driven user interfaces (UIs) have become popular with the rise of LLMs like ChatGPT. Unlike traditional UIs, AI interfaces often involve conversational interactions, dynamic content streaming, and asynchronous backend calls. This introduces unique challenges and patterns for React developers. A typical AI chat interface consists of a frontend (for user input and displaying responses) and a backend (to call the AI model)[1]. The backend is essential to keep API keys and heavy processing off the client for security and performance[1]. Tools like Vercel’s AI SDK make it easier to connect to providers (OpenAI, HuggingFace, etc.) and stream responses in real-time[2]. We’ll explore how to set up both a Next.js app and a Vite (React) app to handle these concerns, and discuss best practices that apply to both.
Key patterns covered:
- Structuring AI prompt data and managing conversation state
- Streaming AI responses to the UI for real-time feedback
- Debouncing user input to avoid spamming the API
- Error handling and fallbacks in the UX
- Reusable UI components for messages, inputs, and more (with TailwindCSS)
- Architectural differences: Next.js route handlers vs. Vite with a Node backend
By the end, you’ll be equipped to build a responsive, robust AI-powered UI in React, whether you prefer Next.js or a Vite toolchain.
Project Setup and Tools
Before diving into code, ensure you have the necessary packages and configurations:
-
React & Vite: Initialize a Vite + React project (e.g.
npm create vite@latest my-ai-app -- --template react). For Next.js, you can usenpx create-next-appor the Next 13 App Router templates. Both will work – we’ll highlight differences as we go. -
TailwindCSS: Set up Tailwind in your project for quick styling. In Next.js, follow the official Tailwind setup (add
tailwindcssand configuretailwind.config.jsfor Next). In Vite, installtailwindcssand import the Tailwind output CSS in your app. Tailwind utility classes will style our chat interface elements. -
OpenAI API & Vercel AI SDK: Install OpenAI’s library or the Vercel AI SDK. We will use Vercel’s AI SDK (
npm i ai) which provides helpful React hooks (useChat,useCompletion) and server utilities[3]. This SDK is framework-agnostic, working with Next.js, vanilla React, Svelte, and more[5]. It simplifies streaming and state management, and is free/open-source. Alternatively, you can call OpenAI’s REST API directly via fetch – but the SDK saves a lot of boilerplate. -
API Keys: Get your OpenAI API key from the OpenAI dashboard and store it safely. In Next.js, put it in
.env.local(e.g.OPENAI_API_KEY=sk-...) and never commit it. In a Vite app, do not expose the key in client code – instead, use a backend proxy or environment variable on the server. We’ll set up a server function to keep the key private.
With these ready, let’s examine how to integrate the AI backend in each framework.
Setting Up AI Endpoints (Next.js vs. Vite)
Next.js Implementation: Next.js (especially with the App Router in Next 13) allows us to create route handlers as serverless functions. We can define an API route that the React front-end will call for AI responses. For example, create pages/api/chat.js (for Pages Router) or app/api/chat/route.ts (for App Router) to handle chat requests. Using the Vercel AI SDK on the server, the code might look like this (TypeScript in App Router):
// app/api/chat/route.ts (Next.js)
import { Configuration, OpenAIApi } from 'openai-edge'; // Edge-optimized OpenAI client
import { OpenAIStream, StreamingTextResponse } from 'ai'; // Vercel AI SDK utilities
export const runtime = 'edge'; // Use Vercel Edge for low-latency streaming
const config = new Configuration({ apiKey: process.env.OPENAI_API_KEY });
const openai = new OpenAIApi(config);
export async function POST(req: Request) {
const { messages } = await req.json(); // Expect messages array from client
// Call OpenAI's Chat Completion API (streaming)
const response = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
stream: true,
messages: messages.map((m: any) => ({ role: m.role, content: m.content }))
});
// Convert OpenAI response into a web stream for the client
const stream = OpenAIStream(response);
return new StreamingTextResponse(stream);
}In this handler, we receive a JSON body containing an array of messages (chat history). We call OpenAI’s chat completion with stream: true to get a streaming response, using the OpenAI Edge SDK which is compatible with Vercel Edge Runtime[6]. We then wrap the response in a StreamingTextResponse provided by the AI SDK to pipe it back to the client in chunks[8]. The Next.js API route keeps our API key on the server and streams data efficiently.
Vite (React) Implementation: In a Vite app, there’s no built-in server, so we need to create our own backend for the OpenAI calls. This can be a simple Node/Express server or a serverless function. One approach is to create a separate Express server (run on a different port during development) and proxy API requests to it. For example, we might have a server.js like:
// backend/server.js (Node/Express for Vite app)
import express from 'express';
import { Configuration, OpenAIApi } from 'openai';
const app = express();
app.use(express.json());
const config = new Configuration({ apiKey: process.env.OPENAI_API_KEY });
const openai = new OpenAIApi(config);
app.post('/api/chat', async (req, res) => {
try {
const { messages = [] } = req.body;
// (Optional) Prepend a system prompt for context/persona
const systemMsg = { role: 'system', content: 'You are a helpful assistant.' };
const inputMessages = [systemMsg, ...messages];
// Call OpenAI Chat Completion API (no SDK here, using OpenAI node client)
const response = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
stream: false, // (use streaming in advanced setup, see below)
messages: inputMessages
});
const content = response.data.choices[0].message?.content;
res.json({ content });
} catch (err) {
console.error(err);
res.status(500).json({ error: 'Internal Server Error' });
}
});
app.listen(6000, () => console.log('API server listening on http://localhost:6000'));During development, you can configure the Vite dev server to proxy /api calls to this backend (e.g. in vite.config.js, set server.proxy['/api'] = 'http://localhost:6000')[9]. In production, you could deploy this as a serverless function (on Vercel, AWS, etc.) or container alongside your static front-end. The key is that the React app calls a relative /api/chat endpoint, which the proxy/hosting will route to your server code. This keeps the OpenAI key hidden and allows using Node libraries.
Enabling Streaming in Node: The above Express example returns the full response after completion (stream: false for simplicity). To stream in Node, you can use OpenAI’s HTTP stream: set stream: true and handle the response as a stream of data. This involves reading the response.data stream and flushing chunks to the client with res.write(). Vercel’s AI SDK also provides a low-level AIStream utility that can be used outside Next, but a simpler method on Node is to use the OpenAI HTTP API directly via fetch() or the SDK’s response.data as an AsyncIterator. Given the complexity, many developers building non-Next apps opt to use web frameworks that support streaming or leverage libraries to help parse the event stream of tokens. If you choose to stick with full responses (no streaming), the UI patterns still largely apply – but streaming greatly improves UX, as we’ll see next.
Prompt Handling and Conversation State
At the heart of any AI interface is prompt management – assembling user input (and context) into a prompt or message sequence for the AI model. In a chat scenario, we maintain a list of messages, each with a role and content. OpenAI’s Chat API expects messages in the format { role: 'user' | 'assistant' | 'system', content: string }. We typically start with a system message (to set the assistant’s behavior or context), followed by alternating user and assistant messages as the conversation progresses[10]. This list of messages is sent with each request to give the model context.
State management in React: We can store the conversation in component state. For example, using the Vercel SDK’s React hook:
// Inside a React component (Next.js or Vite)
import { useChat } from 'ai/react'; // from Vercel AI SDK
function ChatInterface() {
const { messages, input, handleInputChange, handleSubmit } = useChat();
// ...
}The useChat hook handles a lot for us: it manages the messages state (an array of message objects), an input state for the current text input, and provides handleInputChange and handleSubmit helpers[12]. By default, useChat() will POST to /api/chat when you submit, aligning with the Next.js route we created[14]. (If using this hook in a Vite app, you should override the api endpoint in the hook options, e.g. useChat({ api: 'http://localhost:6000/api/chat' }), to point to your backend.)
Manual state handling: If you aren’t using useChat, you can manage state with useState or context. For instance, in a simple React app you might use const [messages, setMessages] = useState([]). On form submit, call your API and then update the messages array by appending the user query and the assistant’s response. The Vercel hook abstracts this, but it’s essentially doing the same – plus handling streaming updates (more on that next).
System prompts and context: A common pattern is including an initial system message describing the assistant’s role or knowledge base. For example, if building a docs helper, system content might be “You are a documentation assistant. Answer with examples from the docs.” Our Express sample showed how to prepend a system message on the server side[15]. Alternatively, you can initialize the conversation state with a system message in React (the Vercel hook has an initialMessages option). The system prompt helps maintain consistent behavior, which is especially important for AI-assisted UI features (like an assistant that follows certain rules).
Single-turn vs multi-turn: If your interface is a single question answering (no conversation memory), you could use the useCompletion hook from the Vercel SDK instead. useCompletion is designed for one-off prompts that produce a completion (similar to GPT-3 text completion). It still streams the answer, but it doesn’t maintain a message history. For chatbots and multi-turn dialogs, useChat is the go-to pattern, since it retains and sends the message history on each request.
In summary, structure your prompt as a series of messages. Manage that state in React (either manually or via a custom hook). Always include the necessary context (like system role or conversation memory) for the AI to produce relevant answers.
Streaming AI Responses to the UI
One hallmark of modern AI UI is streaming output: as the AI generates tokens, the user sees the reply appearing in real-time. This is crucial for better UX because model-generated answers can be lengthy or slow. Instead of waiting many seconds in silence, streaming lets us display partial results immediately[16].
How streaming works: When we enabled stream: true on the OpenAI API, the response is sent as a sequence of chunks (data events) rather than one JSON blob. The Vercel AI SDK simplifies consumption of these chunks. On the server, we turned the response into a text stream (StreamingTextResponse), which essentially sends a text stream over HTTP to the client. On the client side, the useChat hook (or useCompletion) handles reading this stream and updating the messages state incrementally as new text arrives. Under the hood, it uses the Web Streams API or Server-Sent Events to append tokens to the last message.
If you implement streaming manually in React (without the SDK), you would do something like: call fetch on your /api/chat and then get a reader for response.body. As chunks come in, decode them and update component state. For example:
// Pseudocode for manual stream reading (client-side)
const res = await fetch('/api/chat', { method: 'POST', body: JSON.stringify({ messages }) });
const reader = res.body.getReader();
const decoder = new TextDecoder();
let partial = "";
while(true) {
const { value, done } = await reader.read();
if (done) break;
partial += decoder.decode(value);
setAssistantMessage(partial); // update the latest assistant message with new text
}The SDK’s hooks do this for you, managing the message assembly and re-rendering on each chunk. As a developer, you simply render the messages array – the latest message will grow as text streams in. This gives a fluid effect of the AI “typing” an answer.
Auto-scrolling: One UX detail when streaming is ensuring the latest message is visible. If the conversation overflows the container, new messages might appear off-screen. A pattern to handle this is auto-scrolling the message container on update. You can achieve it with a useEffect watching the messages array length, and scrolling a ref to bottom when a new message arrives. Vercel’s AI Elements components (discussed later) include a Conversation container that handles auto-scroll for you[18].
Partial rendering and completion: It’s good practice to show a visual indicator during streaming – for example, a blinking cursor or “AI is typing…” message. This can be as simple as a CSS animation or a small component rendered when a response is in progress. The AI Elements library even offers a TypingIndicator component for this purpose[20]. Once the stream finishes, you might remove the typing indicator or finalize the message display (e.g., ensure markdown is properly rendered, code blocks highlighted, etc., which we’ll address in UI components).
In summary, prefer streaming for AI responses to enhance responsiveness. The combination of a streaming-enabled API endpoint and React state updates gives the user a feeling of a fast, interactive AI. Both our Next.js and Vite setups support streaming: Next.js via built-in support with StreamingTextResponse and Vite via a custom implementation using Node streams or SSE. With streaming in place, let’s consider handling user input more effectively.
Input Handling and Debouncing
User input is typically collected via a text field (and maybe a “Send” button or pressing Enter). For chat interactions, you usually send the query when the user submits the form. In some AI applications, however, you might want to react to input continuously – for example, autocomplete suggestions, real-time validation by AI, or search-as-you-type with AI answers. In such cases, debouncing is an important pattern.
Why debounce? Calling the OpenAI API (or any AI service) on every keystroke would be extremely inefficient and costly. Debouncing delays the API call until the user has stopped typing for a short period, preventing a flurry of calls for intermediate input states[21]. The typical approach is to use setTimeout and clearTimeout or a utility like Lodash’s _.debounce around the function that triggers the API.
For instance, imagine an “AI assist” feature that provides suggestions as the user composes an email. You could use a useEffect hook like:
const [draft, setDraft] = useState("");
useEffect(() => {
if (!draft) return; // no input, no action
const timeout = setTimeout(() => {
// Call OpenAI completion API to get suggestion for the current draft
getSuggestion(draft);
}, 500); // wait 500ms of inactivity
return () => clearTimeout(timeout);
}, [draft]);In this pattern, as the user types into a controlled input (updating draft state), the effect will reset the timer until they pause. Only when 500ms passes with no new keystroke do we call getSuggestion (which would fetch from an endpoint similar to /api/completion). The result could be displayed as a ghost text or a dropdown of suggestions. This debounced input pattern ensures responsiveness without spamming requests.
For a simple chatbot with explicit “send” action, debouncing is usually not needed – you send when the user hits Enter. However, it’s still useful to disable the input or prevent multiple submissions while an AI response is in progress. The useChat hook provides an isLoading flag for this purpose (not shown in earlier snippet but available), or you can track a loading state manually. Disabling the input or button during streaming prevents overlapping AI calls (which could scramble message order or overload your API quota).
In summary, use debouncing when implementing auto-query-on-input features, and always guard against rapid repeated submissions. A smooth AI UX often means balancing responsiveness with rate limiting, and debouncing is a key tool for that.
Error Handling and Resilience
Robust error handling is vital in AI applications, as many things can go wrong – network issues, API errors (rate limits, token quota), or even model refusals. A good design pattern is to treat the AI call as an uncertain operation and plan for failures:
-
Try/Catch around API calls: On the server (Next API route or Express), wrap the OpenAI call in try/catch. Return a proper error response (with HTTP 500 and maybe an error message in JSON) if something fails[22]. This ensures the client always receives a response, even if it’s an error object.
-
Client-side error state: The React component should handle cases where the response indicates an error. For example, the Vercel hook
useChataccepts anonErrorcallback option, or you can catch the promise fromsendMessage. In the Next.js example from Vercel, they do:
try {
await sendMessage({ text: input });
} catch (error) {
console.error("Failed to send message:", error);
// Show an error message to the user
}[24]. In a custom implementation, you might set an error piece of state if the fetch returns { error: "..."}. Then conditionally render an error banner or a message bubble indicating the failure.
-
User feedback: Always inform the user when something goes wrong. A common UX pattern is to display the error inline in the chat – e.g., as a special “system” message saying ”Sorry, something went wrong. Please try again.” (perhaps styled in red or with a warning icon). This makes it part of the conversation flow. Alternatively, use a toast notification or modal for errors. Since our app uses Tailwind, we can quickly style an error message or use a pre-built component (AI Elements includes some support for error states as well).
-
Retry mechanism: Depending on the error cause, consider allowing the user to retry. This could be a “Try again” button that resends the last user prompt. If using
useChat, you might just callsendMessageagain with the same text. Be careful to not create duplicate messages in state – you may want to replace the failed response with a new one. -
Validation errors: If the user input itself is problematic (too long, empty, etc.), validate on the client before calling the API. E.g., disable send on empty input, or truncate inputs that exceed some length. This prevents certain error cases altogether (OpenAI has max token limits, so extremely long prompts should be handled or refused gracefully).
Remember that OpenAI API usage costs money and has rate limits. If your interface could generate rapid consecutive calls (e.g., user hitting enter multiple times, or a bug causing loops), implement safeguards. The patterns above (disabling input during processing, debouncing, etc.) help avoid spamming the API. For critical applications, you might also implement cancellation – e.g., if the user sends a new query while a previous answer is streaming, you could cancel the old request. The Vercel SDK’s useChat provides a stop() method to cancel an ongoing stream if needed.
In short, fail gracefully: catch errors, inform the user, and allow recovery. This turns a potentially confusing blank screen or console error into a manageable part of the user experience.
Building the UI: Components and Styling Patterns
With the backend and logic in place, the focus shifts to the frontend UI components. Reusable component design is a key pattern: we want to separate the presentation of the chat from the logic of fetching data. This allows using the same components in both Next.js and Vite apps with minimal changes.
When an AI model is on the other side of the conversation and it’s full of reasoning traces and tool calls (i.e., it’s agentic), chat UI design becomes more complex. The interface needs to handle not just text responses but also intermediate steps, function calls, and structured outputs:
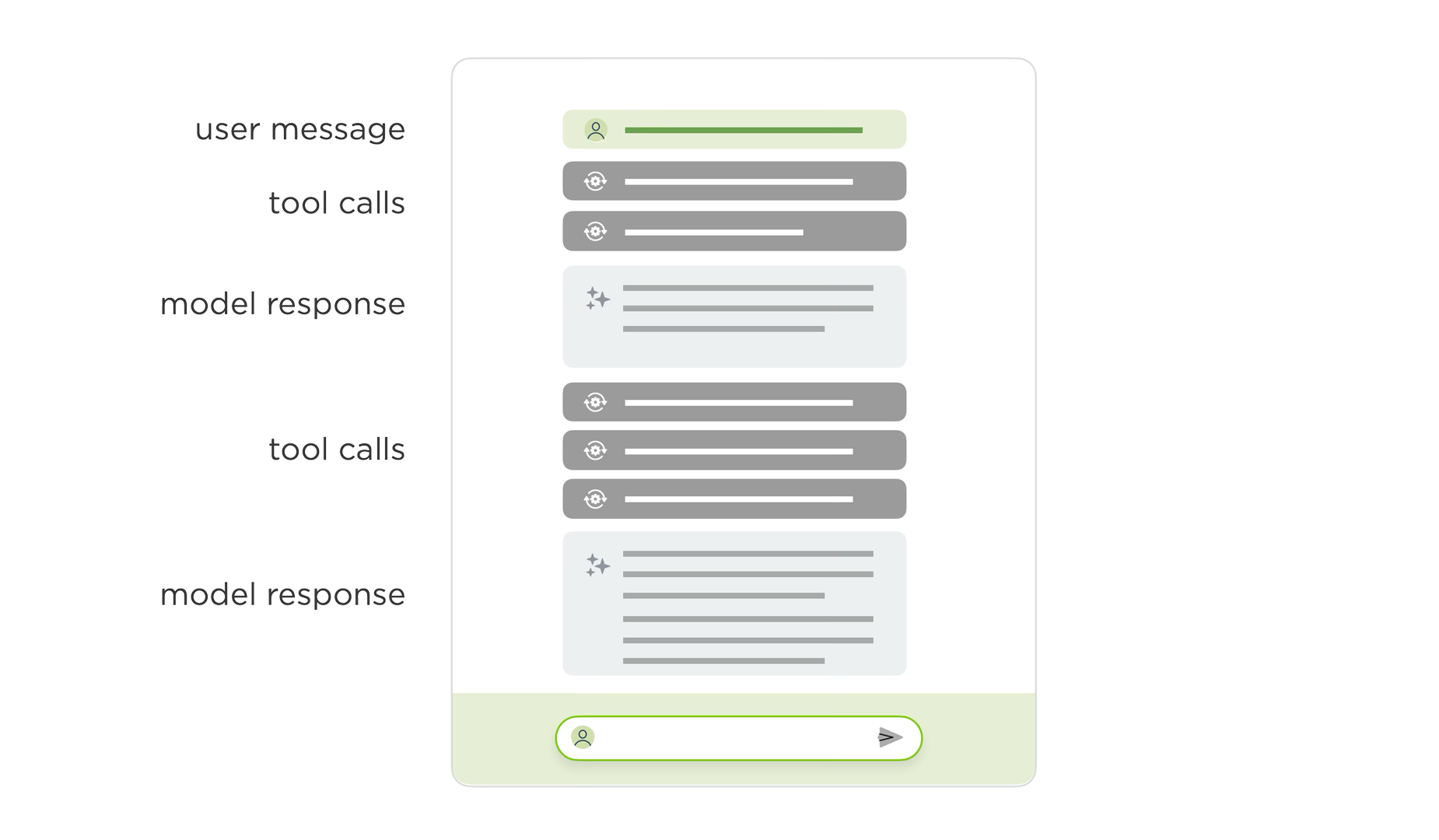
Image Source: https://www.lukew.com/ff/entry.asp?2135
A well-designed chat interface typically follows established patterns for message layout, input positioning, and visual hierarchy:
Image Source: https://sendbird.com/blog/resources-for-modern-chat-app-ui
Chat message components: A common approach is to create a ChatMessage component that renders a single message bubble. It receives props like role (user or assistant) and content (the text). Based on role, you style it differently – e.g., user messages on the right with a blue background, assistant messages on the left with a gray background. Using TailwindCSS:
function ChatMessage({ role, content }) {
const isUser = role === 'user';
return (
<div className={`flex ${isUser ? 'justify-end' : 'justify-start'} mb-2`}>
<div className={`max-w-xl px-4 py-2 rounded-lg ${
isUser ? 'bg-blue-500 text-white' : 'bg-gray-200 text-gray-900'
}`}>
{content}
</div>
</div>
);
}This component is purely presentational – it has no knowledge of how messages are fetched or stored. You can compose a ChatMessages list component that maps over the messages array and renders <ChatMessage /> for each.
Input component: Similarly, create an InputBox component for the user input. This could be a controlled input tied to input state, with an onSubmit handler:
function InputBox({ value, onChange, onSubmit, disabled }) {
return (
<form onSubmit={onSubmit} className="flex gap-2">
<input
type="text"
value={value}
onChange={onChange}
disabled={disabled}
className="flex-1 border rounded px-3 py-2"
placeholder="Type your message..."
/>
<button type="submit" disabled={disabled} className="bg-blue-500 text-white px-4 py-2 rounded">
Send
</button>
</form>
);
}Composition: The parent ChatInterface (or ChatPage) component composes these:
function ChatInterface() {
const { messages, input, handleInputChange, handleSubmit, isLoading } = useChat();
return (
<div className="flex flex-col h-screen max-w-2xl mx-auto p-4">
<div className="flex-1 overflow-y-auto">
{messages.map((msg, i) => (
<ChatMessage key={i} role={msg.role} content={msg.content} />
))}
</div>
<InputBox
value={input}
onChange={handleInputChange}
onSubmit={handleSubmit}
disabled={isLoading}
/>
</div>
);
}This separation of concerns makes it easy to test and swap UI parts. The logic (useChat) is decoupled from the display components.
Vercel AI Elements (Pre-Built Chat UI Components)
Building a polished chat UI from scratch takes effort. Vercel’s AI Elements library offers a set of ready-made React components specifically designed for AI chat interfaces[18]. These include:
- Conversation: A container that renders a list of messages with auto-scrolling.
- Prompt: An input component optimized for chat prompts.
- TypingIndicator: Shows when the AI is “thinking” or streaming a response.
- ErrorBoundary/ErrorMessage: Handle and display errors gracefully.
Using AI Elements can save significant development time. For example, instead of building your own auto-scrolling conversation container, you can use:
import { Conversation, Prompt, TypingIndicator } from '@vercel/ai-elements';
function ChatApp() {
const { messages, input, handleInputChange, handleSubmit, isLoading } = useChat();
return (
<div className="h-screen flex flex-col">
<Conversation messages={messages} />
{isLoading && <TypingIndicator />}
<Prompt
value={input}
onChange={handleInputChange}
onSubmit={handleSubmit}
/>
</div>
);
}The AI Elements library handles many UX details automatically – scrolling, accessibility, animations – letting you focus on the AI logic. It’s especially useful for rapid prototyping or production apps where you want a professional look with minimal custom styling.
Putting It All Together
Let’s summarize the patterns and architecture:
-
Backend API Route: Whether using Next.js route handlers or a separate Express server, create an endpoint (e.g.,
/api/chat) that receives messages, calls the AI model, and streams the response back. -
State Management: Use the Vercel AI SDK’s
useChathook (or roll your own withuseState) to manage the conversation state. Keep track of all messages and the current input. -
Streaming: Enable streaming on both server and client for responsive UX. The SDK handles most of this; if rolling your own, use the Fetch API’s streaming capabilities.
-
Debouncing & Rate Limiting: For features like autocomplete, debounce API calls. For chat, disable input during response streaming to prevent overlapping requests.
-
Error Handling: Wrap API calls in try/catch, provide user feedback on errors, and consider retry mechanisms.
-
Reusable Components: Build presentational components (
ChatMessage,InputBox) that are decoupled from data-fetching logic. Consider using AI Elements for production-ready components. -
Styling: Use TailwindCSS (or your preferred styling solution) to create a clean, responsive chat interface.
Architectural Comparison: Next.js vs. Vite
| Aspect | Next.js | Vite + Node Backend |
|---|---|---|
| API Routes | Built-in (pages/api/ or app/api/) | Separate Express/Node server required |
| Streaming | Native support with Edge Runtime | Manual implementation with res.write() |
| Deployment | Vercel (optimized) or self-host | Deploy frontend (static) + backend separately |
| Complexity | Lower (all-in-one) | Higher (two codebases) |
| Flexibility | Framework conventions | Full control |
For most AI chat applications, Next.js provides a simpler developer experience with its integrated API routes and streaming support. However, if you have an existing Vite/React app or prefer more control, the patterns described here work well with a separate backend.